For a number of years now, I’ve been hacking on several side-projects in parallel, whenever I can.
They try to scratch different itches and explore different ideas, but they all build on a common, evolving intuition about how I’d like to think about building software. Recently, these projects have started converging into a somewhat unified Ruby stack.
I’ll describe the different projects here. What they are, how they work together, and what they could be.
Sourced
Sourced is the oldest of the projects, and it’s undergone multiple incarnations (including in different languages) since at least 2018, extracted from an Ecommerce side-project from 2016.
# A Sourced "decider" gathers state from past events
# handles a new command and relies on the derived state
# to decide how to handle the command
class CourseDecider < Sourced::Decider
# Defines the consistency boundary
partition_by :course_name
# Initial state factory (receives partition values hash)
state do |_partition_values|
{ name_taken: false }
end
# Evolve state from events history
evolve CourseCreated do |state, _event|
state[:name_taken] = true
end
# Command handler — enforce invariants, then produce new events
command CreateCourse do |state, cmd|
raise "Course '#{cmd.payload.course_name}' already exists" if state[:name_taken]
event CourseCreated,
course_id: cmd.payload.course_id,
course_name: cmd.payload.course_name
end
end
In its current form it’s a toolkit for building event-sourced, eventually-consistent backends.
Event Sourced means that data is stored as a sequence of events representing what happened in the domain, and any current state is derived from said events.
Eventually Consistent means that events are processed asynchronously by Sourced’s runtime, and this is the default mode of operation. Event Sourcing itself is a simple idea, but it really comes to life (in my opinion) when modeling workflows that happen over time, and that takes quite a lot of extra architecture to get right.
Because events are stored durably, this means that different event producers and consumers work at their own pace and are temporally decoupled from each other. It also means that you can “replay” consumers (for example for building views from historical events, or adding new consumers that “catch-up” with the event log).
The Sourced runtime manages keeping track of where in the global event log each consumer is, dispatching new events to the right consumers, retries, concurrency and ordering guarantees. etc. There’s some fairly sophisticated locking and claiming mechanism involved, but once this is solved at the library level it means that your domain logic can be expressed purely in terms of commands and events (ie. inputs and outputs).
# Testing a Sourced Decider in Given, When, Then format
# Domain logic tested as pure behaviour, no persistence concerns required.
it 'emits DonationStarted with campaign_id' do
with_reactor(Donation, campaign_id:, donation_id:)
.given(Campaign::CampaignCreated, campaign_id:, name: 'X')
.when(Donation::StartDonation, donation_id:, campaign_id:)
.then(Donation::DonationStarted, donation_id:, campaign_id:)
end
Currently, I’m re-architecting the library (for the nth time) around the idea of Dynamic Consistency Boundaries, which has a very interesting take on what it means for software to guarantee “consistency”. The consequences of this approach on how business logic is organised also differ significantly from “traditional” Event Sourcing.
Exploring the full potential of Event Sourcing - and making it ergonomic to use in Ruby - has been my main focus throughout. I think Ruby tends to be dominated by very few programming paradigms (mostly due to most people using the dominant MVC/CRUD framework). Which is a shame, because Ruby is a lovely language suitable for all sorts of ideas. Whatever you think of patterns like Event Sourcing, I think it’s healthy to expand the inventory of tools in our mental toolbox.
In particular, I’m very interested in how temporal modeling changes (and possibly simplifies!) the way we think about software design.
For more on this:
- A talk at Baltic Ruby 2025 about the high-level ideas and design behind Sourced.
- A talk at the London Ruby User Group about Durable Messaging and lower level APIs in Sourced.
Sidereal
Sidereal was extracted from web apps I was writing to demo Sourced backends, but it quickly morphed into a persistence-agnostic toolkit for building Ruby web apps that are reactive, collaborative, and eventually-consistent by default.
# A tiny TODO app in Sidereal
class TodoApp < Sidereal::App
session secret: 'a' * 64
layout Layout
handle AddTodo
handle RemoveTodo
command AddTodo do |cmd|
TODOS[cmd.payload.todo_id] = Todo.new(todo_id: cmd.payload.todo_id, title: cmd.payload.title, done: false)
dispatch Notify, message: "Added: #{cmd.payload.title}"
end
command Notify do |cmd|
# Simulate slow operation, IO, APIs, etc
sleep 3
end
command RemoveTodo do |cmd|
item = TODOS[cmd.payload.todo_id]
item.done = true
dispatch Notify, message: "Done: #{item.title}"
end
page TodoPage
end
The main idea is that all operations are “commands” that are decoupled from the transport and execution layer. You just define a command and its handler (basically a little function with typed inputs), and the Sidereal runtime makes sure to run it for you. What this basically means is that there’s no distinction between a “controller” that runs as part of the request cycle, a “background job” that runs asynchronously in the background, or a task that’s run in a terminal or automation. The goal is that there shouldn’t be extra cognitive load when modeling workflows where some steps may return to the UI immediately, while others may run long or retryable tasks “in the background”. It’s just commands that you can stitch together one after the other, and the runtime handles the execution layer.
I wrote more about my reasoning here.
The implication of this “async by default” mode is that the library needs to provide a way for the UI to seamlessly update itself as commands are run in the background. Sidereal provides a unified API for Page objects to update themselves when the relevant commands are run.
# Page objects register what commands should trigger re-renders
# Re-render the page when a todo is added
on AddTodo do |_evt|
browser.patch_elements TodoList.new(TODOS.values)
end
# Re-render a sub-component
on Notify do |cmd|
browser.patch_elements ActivityItem.new(cmd), mode: 'append', selector: '#feed'
end
on RemoveTodo do |_evt|
browser.patch_elements TodoList.new(TODOS.values)
end
This means that there’s no split-brain abstractions needed in the frontend depending on where the operation was run and how the responses are collected. All that matters is that something happened in the domain, and the UI should reflect it.
To accomplish this, Sidereal is built around a version of CQRS, where commands (the “write” side) are sent to the backend in a fire-and-forget way, and the UI (the “read” side) is eventually notified of command completion so that it can update itself.
The UI keeps an open SSE connection to the backend. When new notifications arrive, Ruby Page objects can choose to re-render themselves (or parts of themselves) and push the rendered HTML back to the UI over the SSE connection. The UI only needs a tiny bit of Javascript (the fantastically minimal Datastar, for which I wrote the Ruby SDK).
The whole framework is built on top of fairly simple interfaces and has no network dependencies. The default implementations rely on the file-system and unix sockets, for single-node setups. I’ll explore networked and/or database versions once I’m happy with the APIs, but SQlite, Postgres, NATS and Redis are all good options.
I’m still actively working on this library, and the APIs might change in future. But the core principle remains that, once you limit all entry-points into a single, “command” interface decoupled from the execution layer, a lot of simplification can flow from there, both mental and technical.
Here you can see a simple DSL to dispatch commands on a fixed schedule.
schedule 'Flash sale campaign' do
at '2026-05-10T10:00:00' do |cmd|
# Fires once at this exact moment.
dispatch OpenSale, sale_id: 'flash-2026'
end
at 'every day at 9am' do |cmd|
# Recurring — fires daily until the next concrete step.
dispatch SendDailyReminders
end
at '10d' do |cmd|
# Fires once at "previous concrete + 10 days".
# This concrete time also closes the recurring step above.
dispatch CloseSale, sale_id: 'flash-2026'
end
end
- A talk at Wroclove.rb 2026 about Sourced and Sidereal.
Steppe
Steppe is a toolkit for building REST services. The main premise is that an API endpoint is a pipeline of steps. Some steps might validate input parameters, some might run business logic, but from the outside they’re all simple functions that can be composed into more complex operations.
# GET endpoint with query parameter validation
api.get :users, '/users' do |e|
e.description = 'List users'
e.tags = %w[users]
# Validate query parameters
e.query_schema(
q?: Types::String.desc('Search by name'),
limit?: Types::Lax::Integer.default(10).desc('Number of results')
)
# Business logic step
e.step do |conn|
users = User.filter_by_name(conn.params[:q])
.limit(conn.params[:limit])
conn.valid users
end
# JSON response serialization
e.json do
attribute :users, [UserSerializer]
def users
object
end
end
end
These pipelines are based on Plumb, another library I wrote to support input validations and data transformations (also used by Sidereal and Sourced for command schemas). They are architected as Railway-oriented pipelines, so any step can halt processing at any point. This is relied on for validation and auth steps, or your own custom steps.
# Bearer token authentication with scopes
# This just registers a new step that verifies access tokens
# and (possibly) halts processing.
api.bearer_auth(
'BearerToken',
store: {
'admintoken' => %w[users:read users:write],
'publictoken' => %w[users:read],
}
)
Self-documenting
Steppe extends the basic Pipeline objects with data relevant to REST APIs. Then, it can turn the same Ruby definitions into runnable OpenAPI specs, so you get a running API and usable documentation (and client generation) for free.
This also applies to documenting responses. Steppe serializers and “responders” are all turned into JSONSchema objects as part of the OpenAPI spec.
An API without documentation is only half of the story. While other tools require that you craft documentation by hand, or rather awkward OpenAPI integrations, the idea with Steppe is that you write a running specification in one go.
As I use this library in conjunction with Sourced (ie. building APIs for event-driven systems), I expect I’ll be applying similar principles for generating AsyncAPI specifications as well as OpenAPI ones.
MCP-ready
Because Steppe endpoints are designed with reflection in mind from the start, the same REST endpoints can be turned into an MCP and mounted in your Rack server with one line.
# config.ru
require 'steppe/mcp/handler'
# Create an MCP handler from your Steppe service
mcp = Steppe::MCP::Handler.new(MyService)
# Mount as a Rack app
run mcp
Bring your logic
Because it’s pipelines all the way down, Steppe doesn’t prescribe how you should structure your business logic, other than wrapping it in the simple Step interface so that it can be composed into a REST endpoint.
# A custom class to find a user record
class FindAndAuthorizeUser
# The Step interface
# @param conn [Steppe::Result]
# @return [Steppe::Result]
def self.call(conn)
user = User.find(conn.params[:id])
return conn.respond_with(401).halt unless user.can_update_account?
conn.continue(user)
end
end
# Now register it in your endpoint
e.step FindAndAuthorizeUser
Guard your inputs!
Aside from query and payload schemas, you can also define validation/coercion schemas for request headers. Like any other schemas, header schemas also just register steps, which means that you control the order in which parameters, headers, access tokens and anything else is run. You can use these built-in schema validators, or also add your own arbitrary validation steps. Composition is the name of the game.
api.get :list_users, '/users' do |e|
e.header_schema('ApiVersion' => Steppe::Types::Lax::Numeric)
# some more steps
e.step SomeHandler
# add to endpoint's header schema
e.header_schema('HTTP_AUTHORIZATION' => JWTParser)
# more steps ...
end
A note on framework design
Sidereal and Steppe are both HTTP frameworks, in that both are fundamentally designed to handle HTTP requests and route them to some user-provided logic. Yet they expose very different APIs. While Steppe lets you compose steps that handle requests and responses directly, grouped around request paths like in other tools, Sidereal focuses on a much higher-level abstraction of Pages and Commands.
Ultimately, I think I’ll implement Sidereal as a layer on top of Steppe’s request-handling primitives, but building web pages and specifying REST APIs demand focus on very different things, so I think DX should be optimised for what the developer wants to have top-of-mind when using each tool. Frameworks come with their own built-in domain, and the domains of web app-building and API-writing share technical underpinnings but demand different mental models.
Eventlanes
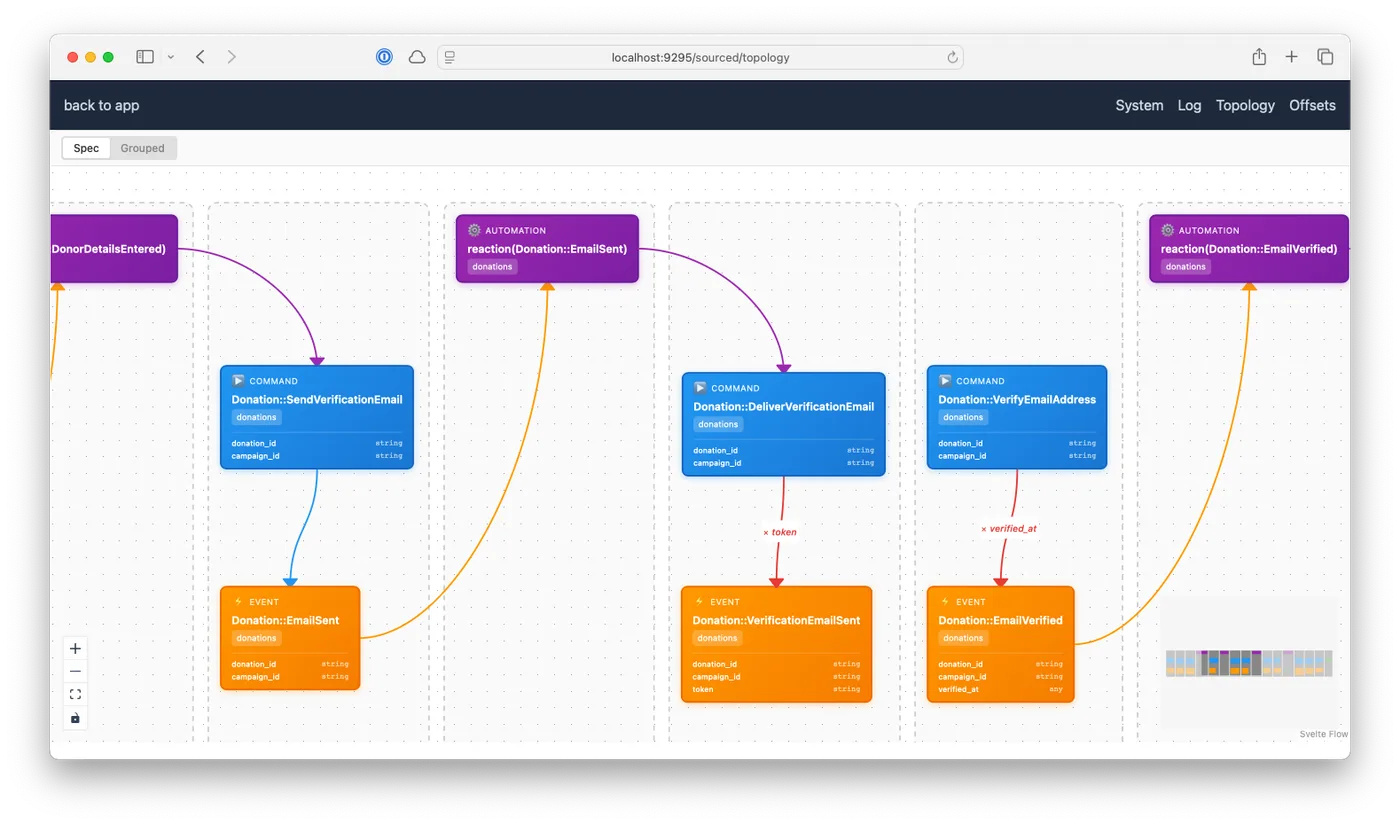
Eventlanes is a tool for diagramming information flows. It started as a web-component to visually document flows in Sourced apps.
It follows Eventmodeling conventions (loosely) to let you model domains in terms of the things the system can do (as opposed to how the parts relate to each other). This way of understanding domain modeling is the common thread in all projects in this article.
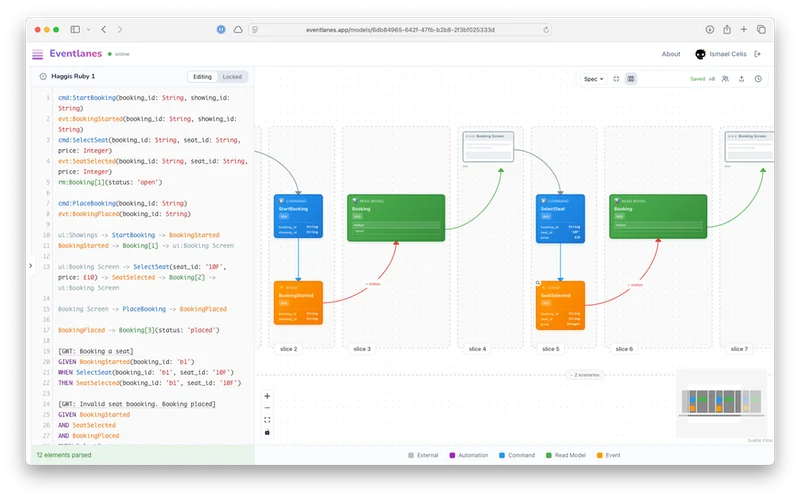
Text-driven diagramming.
The app provides a simple ASCII syntax for defining flows in terms of commands, events, read models (data views), UIs, and others. Then it diagrams those flows as you type them. I was always sketching out little flows in text using these conventions, and I wanted a quick way to visualise them and communicate them.
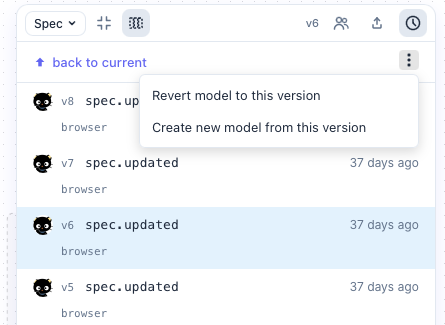
Auditable
Eventlanes’ data backend is built with Sourced, so it’s fully event-sourced. Which means you can “fork” diagrams from any point in time, revert to previous versions, and generally inspect the evolution of your work.
Chat with your domain model
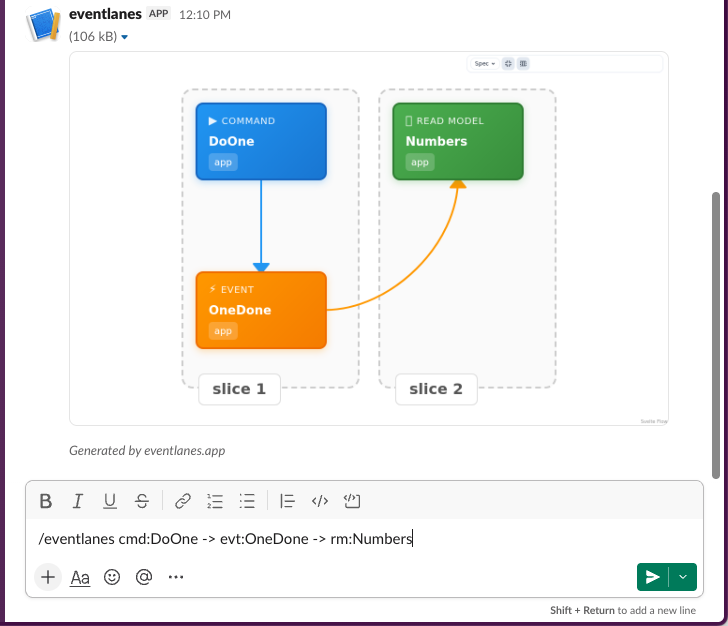
Eventlanes REST API is built with Steppe, which not only gives it free documentation and clients, but also an MCP endpoint. The MCP teaches LLMs how to use the text-based syntax, so that you can discuss, iterate on, and generate diagrams directly from your LLM.
You can actually use this to point an LLM to a pre-existing codebase (in whatever style or stack) and ask the Eventlanes MCP to diagram the different flows in the app. It works surprisingly well and can be a helpful tool in understanding codebases at a high level.
Diagrams, everywhere
This is a tool for communication, so I wanted these diagrams to be portable. The REST API supports taking screenshots of your diagrams, so I “vibe-coded” a quick Github action that allows using the ASCII syntax in READMEs, Pull Requests and comments and it’ll automatically render it into diagrams.
I also have a private Slack bot, so that people can use the ASCII syntax there and have it turned into embedded diagrams.
Shallow models
By thinking of software as timelines of operations that happen in sequences, instead of static, deep graphs of inter-related entities, I think you fundamentally simplify both the mental model and implementation. The number of paths through a graph grows unbounded with the depth of the graph. The possible “public” paths are not described by the graph itself, but scattered over a number of disconnected sources such as tests, controllers, scripts, documentation and institutional knowledge.
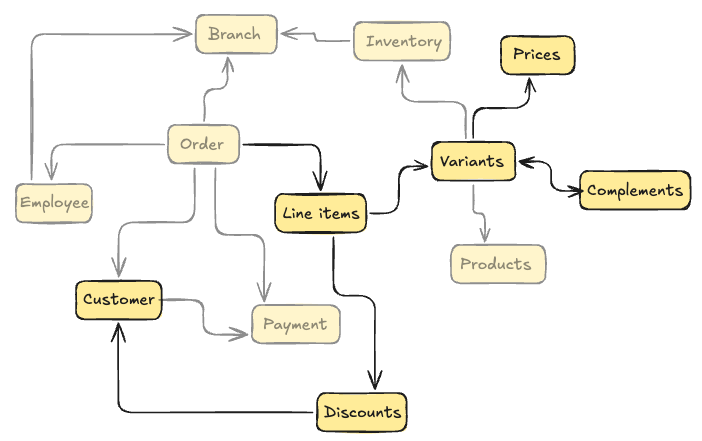
But temporal modeling is of limited use if then you still need to translate it to tools designed with a “graph-oriented” view, or tools that prioritise their own technical domain over your app’s.
Whenever I want to understand how information flows through a codebase I find it grating that I need to tease the flow apart from routes, controllers, jobs and templates that seem to only accidentally relate to each other, with little indication of ordering or causality.
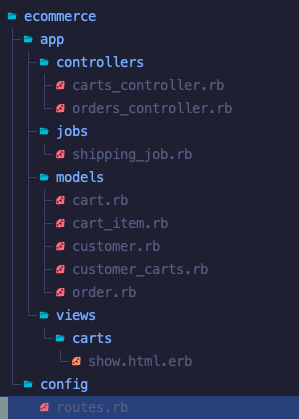
Re-orienting both the model and the implementation around the time axis removes the arbitrary depth implicit in the graph-oriented view, and turns all problems into linear narratives.
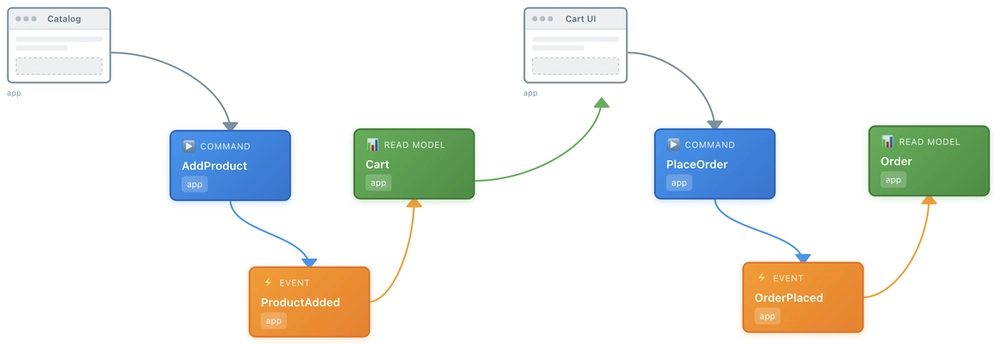
This approach also reduces ambiguity. When both the domain model and the code map to this view, it becomes simpler to understand and produce code (for both humans and machines!).
I think this is the general intuition underlying all these projects, and I expect them to further align in that direction.
Other projects
- I mentioned Plumb, which underpins data transformations, validations and pipelines in the projects above.
- Smidge is a REST API client that bootstraps itself from OpenAPI specs (ex. Steppe APIs!). It can also turn the specification into an MCP, so in theory you could use it to turn a third-party REST API into an MCP…
- Docco is a Ruby gem that turns your project’s README.md into a static documentation site. I use it to build docs for the projects above (Sidereal example). It supports basic custom templating, and the choice between single or multiple pages.
Comments?
Feel free to leave me any comments, questions, or (light) heckling at this Ruby Forum’s page