The conventional distinction between “foreground” request handling and “background” operations in web development is broken, misleading, and incomplete.
There, I said it.
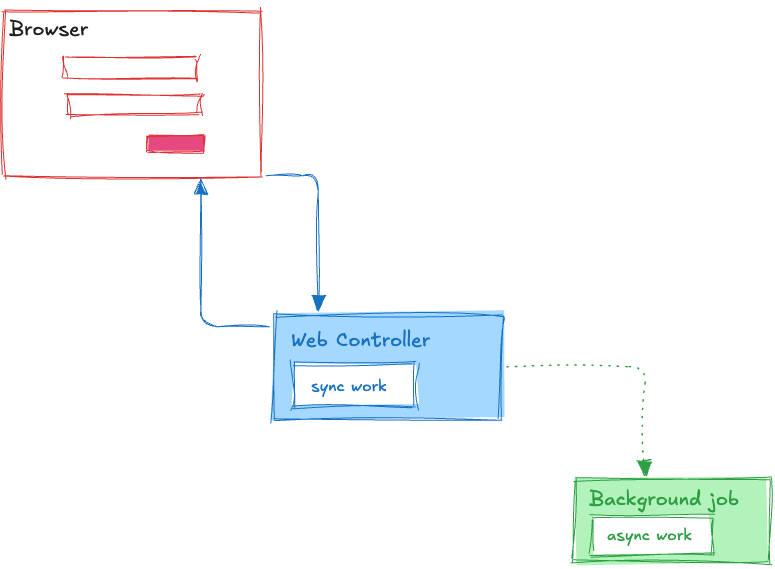
Big MVC™ wants us to believe that some kinds of business logic is synchronous, ie. it runs, changes the state of the system, and returns some kind of result reflecting the change, and some other logic is asynchronous, running in the background, and the caller doesn’t need an immediate response. They are completely different beasts and it’s only right to keep them apart.
In web dev, the former usually takes the form of controller actions or HTTP handlers. The latter, background “jobs” sent to a queue.
As far as I can tell, this distinction originates from practical concerns. Holding an HTTP connection open while slow work is done is costly (especially in some stacks with historically poor concurrency support), and for many kinds of operations it’s desirable to support retries.
So, we do the “fast” things in web controllers, and the “slow”, brittle ones in background jobs.
We model our logic around this boundary. Here I just update a database I own, so it goes in a controller. There, I send an email to I server I don’t own, so I better use my framework’s API for “running stuff in the background”.
# This runs an operation in your app
class SignupsController < ApplicationController
def create
@user = User.create(user_params)
if @user.valid?
UserActivationJob.perform_later(@user)
redirect_to user_url(@user)
else
render :edit
end
end
end
# So does this
class UserActivationJob < ApplicationJob
def perform(user)
account = create_account(user)
UserMailer.activation_link(
user,
account.activation_token
).deliver_later
end
end
Two very different ways to encode domain operations, each with different expectations: the first one should either redirect the browser, or render a template. The second should… What exactly? I’ll come to this in a minute.
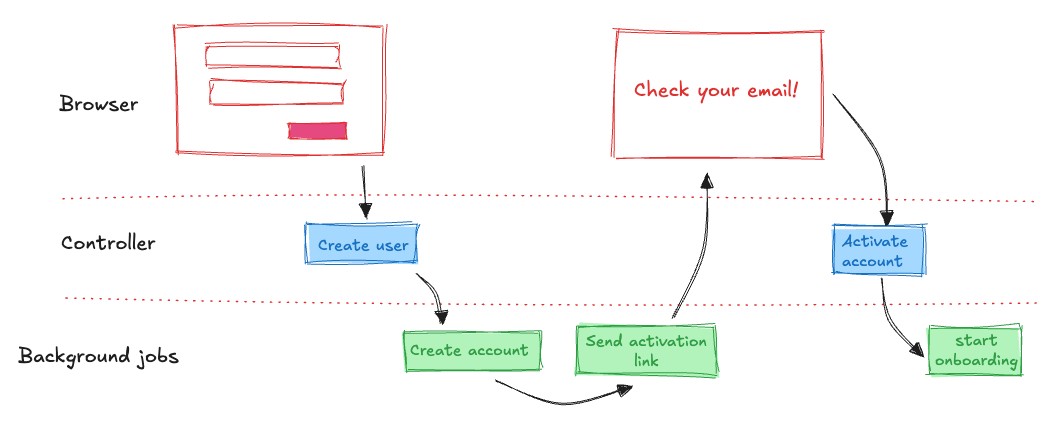
But first: both operations are actually part of the same workflow! The web controller creates a user record, probably in a “pending” or “unverified” state, then it enqueues a job which creates an account and enqueues an email that will send an activation token to the user’s email.
So these are steps in a signup/onboarding workflow, and there’s probably a third step to verify the token and activate the account.
class SignupsController < ApplicationController
def create
# etc...
end
# GET /signup/activation/:token
def activation
# Here we probably also verify token expiry, etc
account = Account.pending.find_by(activation_token: params[:token])
if account
account.activate!
redirect_to dashboard_url
else
render :missing_account
end
end
end
After you go spelunking in various files and manage to piece the whole thing together in your head, this is what it comes down to:

This is what the code should be yelling at me as soon as I open my editor. This is the domain workflow that I need new developers in the team to understand in 30 seconds. Hell, this is what I want to understand myself when I come back to the code after the holidays.
I want the code to lay this out to me in domain terms, not infrastructure terms.
There’s ways to approach this kind of cohesion, of course. You can consolidate the steps into a single place.
# A class representing the Signup workflow
class Signup < ApplicationRecord
belongs_to :user
def self.start(user_params)
signup = new
signup.user = User.create(user_params)
# validations here. Use framework's validations,
# result objects, etc
end
def create_account
# etc
UserMailer.activation(user, account.activation_token).deliver_later
end
def send_activation_link
# etc
end
def self.activate_account(token)
# find signup record by token, etc
end
# More steps?
def start_onboarding
# etc
end
end
The signup object can do all the domain-focused heavy-lifting, and you can decide what parts to invoke in controllers and what parts in light-weight, generic background jobs.
# The controller runs parts of the workflow in a web context
class SignupsController < ApplicationController
def create
signup = Signup.start(user_params)
# check errors, etc
SignupJob.perform_later(signup, :create_account)
end
# GET /signup/activation/:token
def activation
signup = Signup.activate_account(params[:token])
# errors, etc
if signup && signup.active?
redirect_to dashboard_url
else
render :missing_account
end
end
end
# The job runs the parts that we want in the background
class SignupJob < ApplicationJob
def perform(signup, step)
case step
when :create_account
signup.create_account
when :start_onboarding
signup.start_onboarding
end
end
end
Slightly better, perhaps? At least I can read the entire workflow in a single place, separate from the execution infrastructure.
But of course it’s not perfect.
- What happens if a step is retried before it’s finished?
- What happens if the account is created, but the email fails to send? Does the failure recovery strategy depend on whether the step runs in a controller or a job?
- What happens if I skip a step? How are the dependencies between steps declared?
Yes, in this (contrived) example we might want to build a more explicit state machine, idempotent steps, etc. We probably want to split IO-bound operations into individual steps that can be retried separately. It’s great that the idea of durable (background) workflows is getting official support by frameworks. That helps.
But it still feels … Incomplete. What if I want to show the user a new page after the email has been sent, and only if the email has been sent? Where do I keep track of the email’s success or failure?
Perhaps I can have the browser poll the backend for state changes. Perhaps the job can notify the browser via a web socket.
The point is, this kind of mixed workflow is part and parcel of web development, and yet the mental models offered by popular toolkits feel lacking in cohesion. The focus on the machinery of foreground vs background execution obscures the actual flow of information in the design. As a programming model, it doesn’t adequately express the totality of most multi-step workflows on the web. It’s unfinished business.
I want to be able to model workflows in terms of what they do, not where they do it. In fact I want to be able to change the execution context piece-meal without affecting the workflow definition. I want a single way for the UI to reflect the current state of the workflow, wherever it runs.
I think thinking in timelines is the right mental framework, and I think Event Sourcing is the right technical framework (but not the only one).
This is the goal.